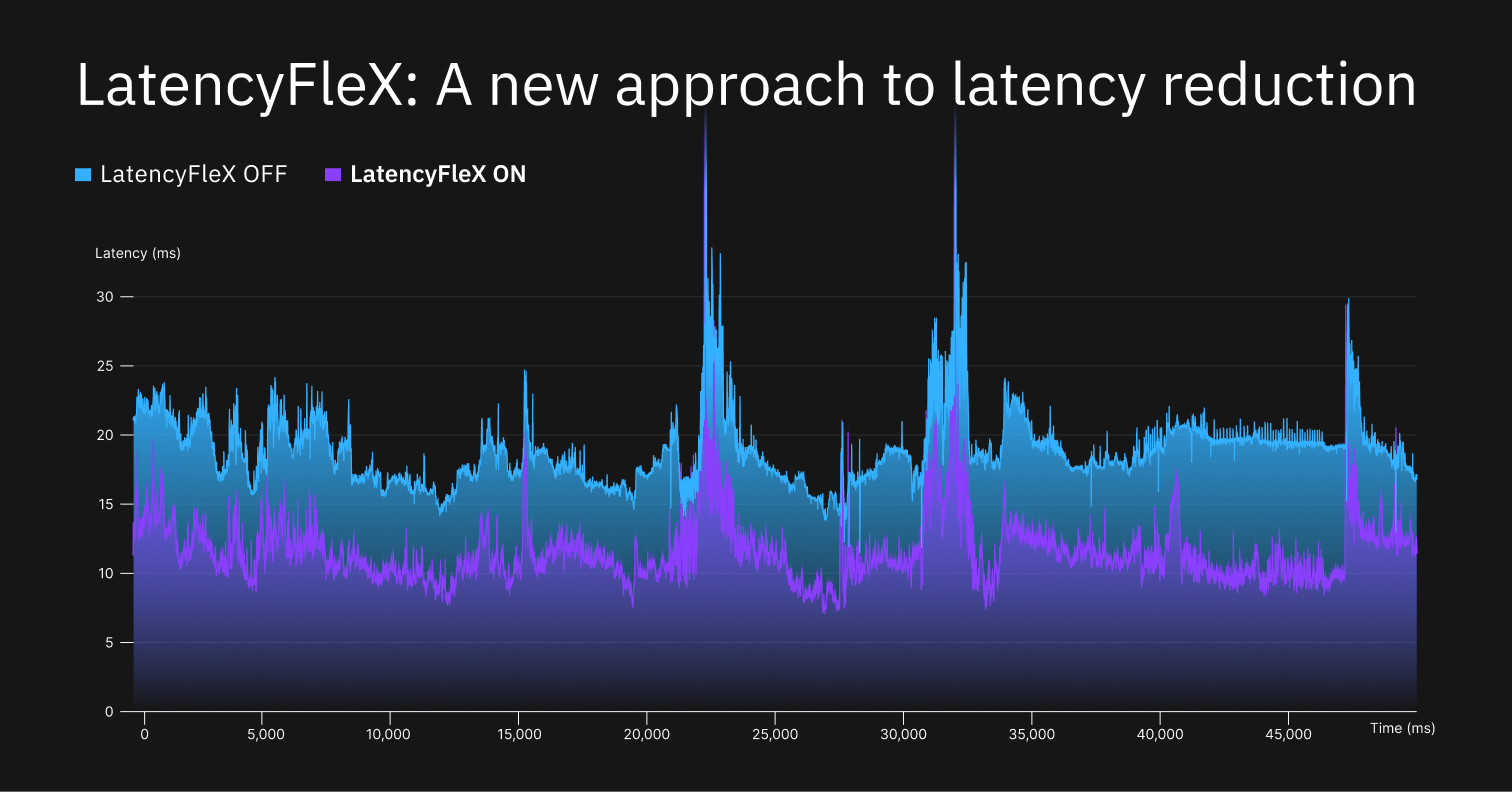
This post describes the inner workings of LatencyFleX, which is a set of libraries that achieves latency reduction for video games, made as a vendor-agnostic alternative to Nvidia Reflex.
A technology called Nvidia Reflex was released in 2020. It drastically improved system latency, by adjusting the pacing of the game’s main thread so that it kept queued GPU work to a minimal amount. If you are not familiar with the tech, I recommend watching this video from Battle(non)sense.
Some time later, I came across Google’s wonderful congestion control algorithm, BBR. BBR was designed to solve a long-standing issue in networking: Bufferbloat. The cause of Bufferbloat was that previously, congestion control relied on packet loss, which was a signal that the buffer is full. As such, these algorithms could end up operating at the worst-case round-trip time. But it turns out that there’s another signal for congestion, that can be utilized as soon as we reach full bandwidth, and it’s called delay. BBR exploits this metric to achieve congestion control at the optimal operation point.
Soon after I gained an understanding of BBR, I realized Bufferbloat shares a lot of properties with the game latency issue. The buffer is called a queue, the RTT is called latency, and the bandwidth is called throughput, frames per second, or something like that. This became the basis of LatencyFleX: using BBR’s idea to run games at the latency-optimal operating point.
In this post, I will analyze BBR’s behavior by breaking it up into two parts, and then describe how these ideas are utilized in LatencyFleX.
Pacing: creating a “CPU-bound” scenario
The first step toward optimal operation is to not pile up the work too fast. To achieve that, BBR measures the “bottleneck bandwidth” and paces packet sending at that rate. Measuring bandwidth is easy: just look at the rate you receive the ACKs. But there’s one catch: you can’t measure a bandwidth higher than what you’re currently pacing at. BBR authors call this the “uncertainty principle”.
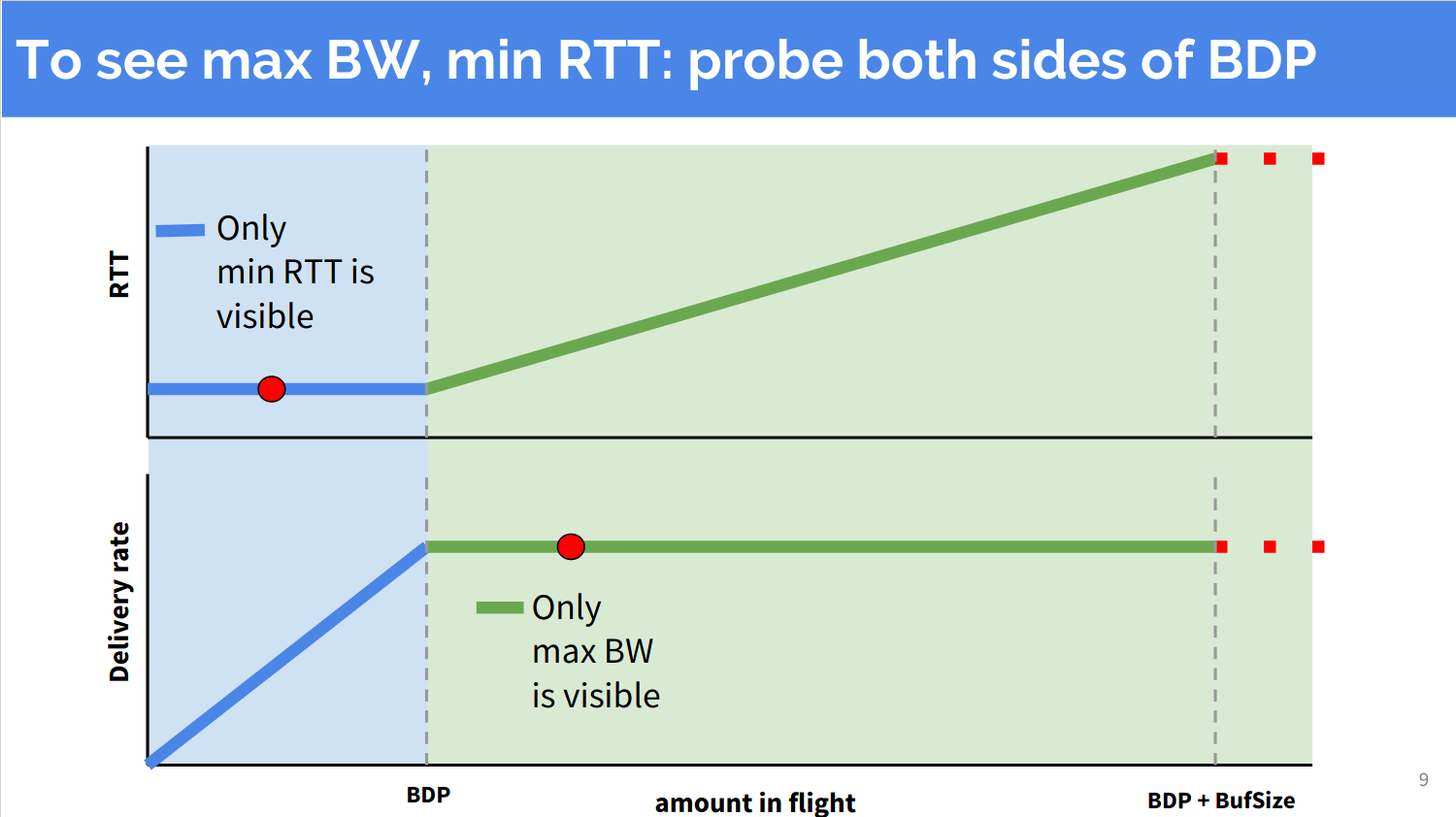
(Image from BBR Presentation)
In order to measure the max bandwidth, BBR periodically enters a “probe bandwidth” mode: it increases packet sending rate temporarily, which creates a queue and allows us to see if more bandwidth is available. Then, it lowers the sending rate by the same amount to keep the average sending rate the same, and to remove any queuing that might have been created during the temporary sending rate bump. The behavior is described by the following figure in the BBR paper:
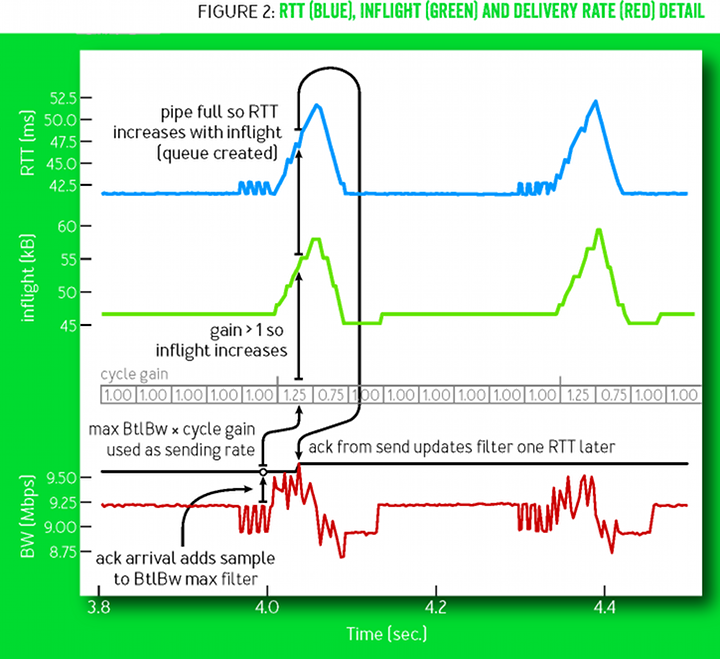
BBR also applies a -1% gain to the average bandwidth, which allows it to gradually reduce the preexisting queue and eventually see the minimum RTT.
In LatencyFleX we use basically the same idea, but at a higher frequency: we run one frame in the “probe frame rate” mode, then use the next frame to drain any queue, then repeat. A crucial difference is that we use a different estimator for throughput and latency. In BBR, bandwidth is measured by $$\widehat{\text{BtlBw}}=\max(\text{DeliveryRate})$$ This worked well for BBR because $\text{DeliveryRate}$ is smoothed over a long window and the variance is low enough. However in LatencyFleX we need to derive the real-time frame rate from the latest frame time values, which is highly noisy. Using the maximum would make the estimator strongly biased. Instead, we use exponentially weighted moving average, which gives an unbiased estimate:
$$\frac{1}{\widehat{FPS}}=\text{ewma}(\text{FrameTime} \mid \text{frame is in ``probe’’ phase})$$
We only sample the frames we tried to make “fast”, or we would be measuring the average frame rate which is equal to our pacing target.
We also apply the negative gain like in BBR. In LatencyFleX we use -1.5% which was determined to be a good balance from testing.
By running the main thread at a lower rate than the bottleneck (which is typically the GPU), we have now created a CPU-bound scenario. This alone will give the sweet latency reduction we want in the steady state. We’re now halfway through the problem! Next, we look at the delay compensator, which actively tries to prevent latency increase in a scenario where latency and frame time dynamically varies.
Delay compensation: keeping the latency always low
The pacer we discussed in the previous section has an issue: it takes a long time for it to adapt to bandwidth decrease. This is because of two reasons:
- Both the windowed-max estimator and EWMA estimator has a certain delay until it adapts to a lower value. Until then, we would continue to pace at a rate over the actual bandwidth.
- Overpacing creates queue (at a rate proportional how much it’s over the limit), and the pacer can only drain queue at a rate equal to the margin we specified (1% for BBR, 1.5% for LFX). The former can be much faster than the latter, and it means that it would take an excessively long time to return to optimal operation.
Therefore, we need something that detects and removes the queue, independently of the pacer. What BBR uses is called “inflight control”: it calculates the “just right” amount of packet inflight (sent but not ACKed yet) that is needed for optimal bandwidth utilization, and blocks sending if ACKs are arriving at a rate slower than anticipated.
This gives a “brickwall” that prevents the latency from increasing indefinitely, as illustrated in the following figure from the BBR paper:
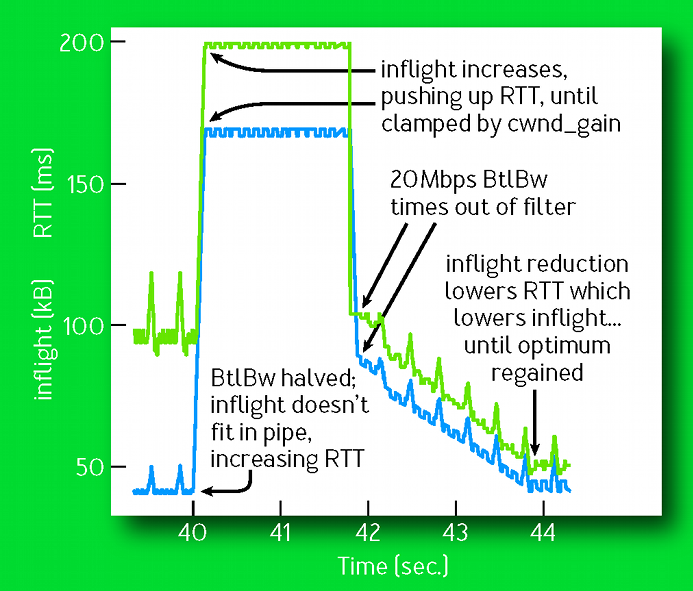
We need something similar in LatencyFleX, but the idea of inflight control cannot be used directly since it quantizes $\text{Bandwidth} \times \text{Delay}$ to an integer, but in the case of games, this would be a small number like 2 or 3, making its behavior suffer significantly from quantization error. We will now describe an algorithm below, that achieves behavior similar to inflight control through a different construct:
- For each frame, we predict the time when it would complete. This is derived by adding the estimated latency to the start time.
- When the completion notification arrives, we compare it to the predicted finish time. If it has completed later than anticipated, we delay frames that begin later by the same amount, but subtracting any previous compensation that we have previously made (so that we don’t compensate for the same delay twice).
The difference between prediction and actual completion is equal to the difference between the latency estimation and ground-of-truth. What this algorithm does is to keep the latency constant: if the latency increases due to queuing, then we try to reduce the queue by the same amount. The latency will spike temporarily until we can react, but it will soon go back to the desired low value.
Let’s further analyze this algorithm’s behavior. When we’re overpacing, the algorithm will throttle the frame rate to the actual bottleneck rate. On the other hand, when the latency increases without a decrease in frame rate, it will end up over-reducing the throughput. The same thing happens with BBR’s inflight control, and this is why I think the algorithm vastly similar in spirit even if the construct is different.
This description omits a lot of complex decisions I made in the actual implementation to achieve stability, in order to avoid making the post too long. I documented as much of them in the code, although some of the stability properties are still not well understood.
Comparing to Nvidia Reflex
One of the motivations that lead to me creating LatencyFleX is that I don’t own an Nvidia GPU but an AMD one. Therefore, I’m unable to provide a direct comparison of performance, but let us discuss a key difference between the overall design of the two middlewares.
A conscious design decision in LatencyFleX is that it treats the entire pipeline as a black-box, only assuming that queuing at the bottleneck would be reflected in the delay. It’s a very powerful model that adapts to every kind of bottleneck, not limited to GPUs.
A common non-GPU bottleneck in recent engines is the render thread. (Render thread sits between the main simulation thread and the GPU queue, issuing the draw calls and building the command buffer.) LatencyFleX is able to reduce latency in such situations without any extra configuration. As game engines increase in complexity, I anticipate that more and more unique kinds of bottlenecks could be born in the future. The following chart illustrates how a game engine pipeline could currently look like.
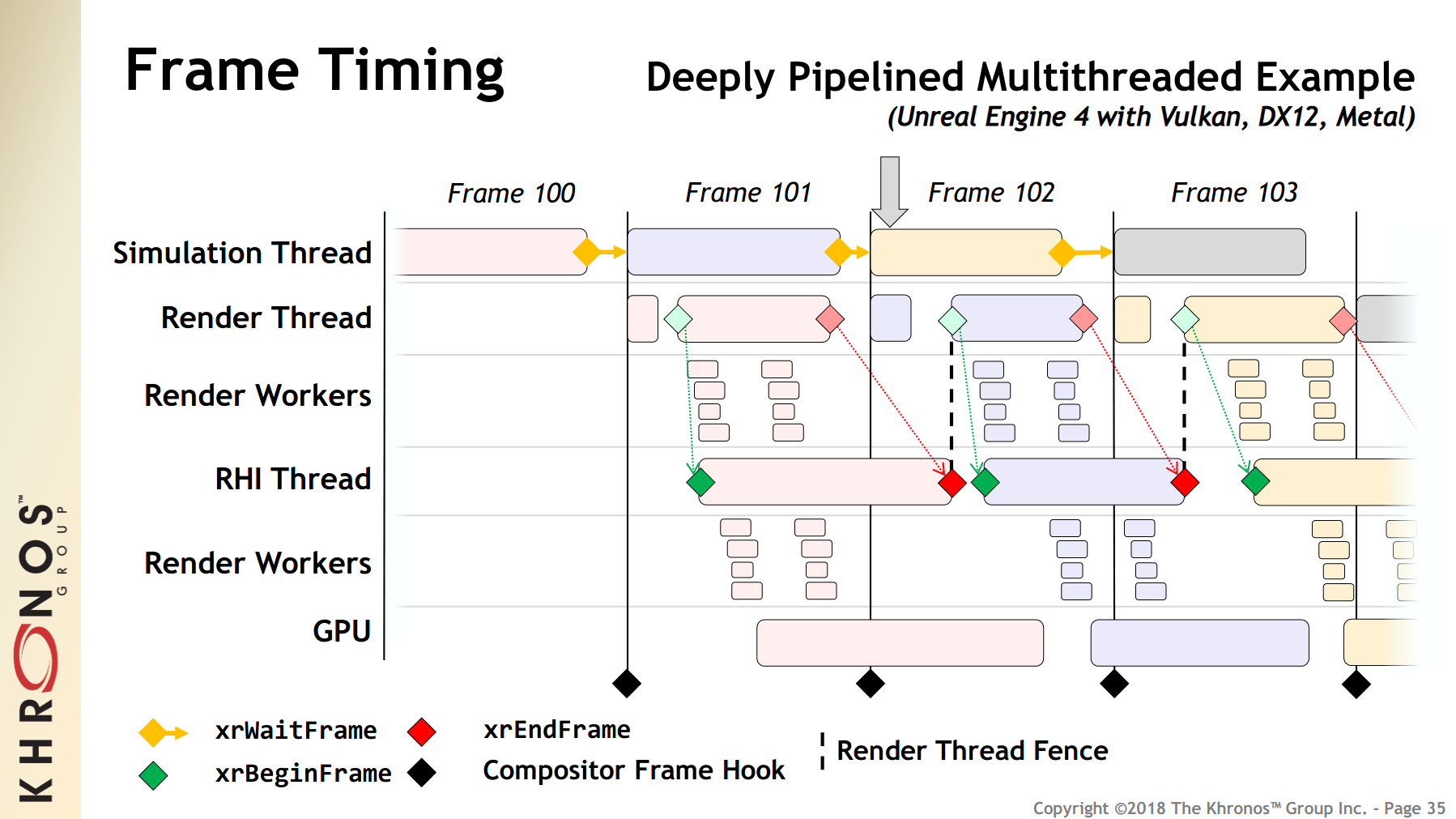
(From OpenXR presentation)
Nvidia Reflex, on the other hand, relies on explicit instrumentation of game engine code. It has execution markers for simulation, render and presentation thread, used to identify communication between threads, as well as an option bUseMarkersToOptimize that enables such optimization. It looks like it has a mode that operates without these markers, but as far as I know all published games seem to use the explicit markers.
In the end, I think Reflex’s explicit instrumentation still has an advantage in terms of stability or frame smoothness, given its more detailed insight on internal queuing. However, LatencyFleX’s trial-and-error measurement approach is also very promising, as it’s highly generalized and future-proof, requires little instrumentation, and still delivers acceptable results.
LatencyFleX is available for Linux users and can be injected into any game that supports Nvidia Reflex, and can also be used with certain games that does not support Reflex but meets certain game engine conditions. If you are interested, please give it a try. In the future, I look forward to developing integrations for game developers, once I’m confident the LFX is stable enough as an end product.
For further reading, I recommend Raph Levien’s Swapchains and frame pacing, which covers a wider range of solutions and tradeoffs on solving the frame pacing issue.